

Radio Advert Analysis for Covid-19
- Lydia Sanyu Naggayi
- June 30, 2020
Ever been seated there listening to the radio and then you hear an advert about how COVID-19 spreads and how to stay safe? At Sunbird AI, that’s music to our ears.
Our most recent project has been monitoring and analyzing Ministry of Health adverts on the spread of COVID-19 and related safety measures.
The analysis is to track whether COVID-19 adverts are played on radio stations and how frequently they are played. This is important because the broadcasting of information to the public about COVID-19 is a priority, in order to keep us healthy and safe.
This project was implemented in a number of steps:
GETTING RADIO DATA
First, we have to have the radio data, and that means listening to a whole lot of radio. More than 300 stations, to be exact. And yes, I’m joking, of course, we did not manually listen to all that radio.
We went through a digital data collection process as described below:
- Compilation of a file with streaming URLs for a number of radio stations whose streaming URLs were easily accessible
- Writing a Python script to get to each of those streaming URLs and record the data for an hour at a time
- Writing a cron job to run this script every top of the hour, for most of the hours of the day
STORING THE DATA
By now you could be wondering about the huge amount of storage space that all this data would take up with time. In order to save storage space, a data retention policy is required. A data retention policy within an organization is a set of guidelines that describes which data will be archived, how long it will be kept, what happens to the data at the end of the retention period, and other factors concerning the retention of the data. In our case here, we store the radio recordings on our server only for the current day. At the end of each day, the recordings are backed up to cloud storage and then deleted from the server.
ANNOTATING
Before fingerprinting the recordings, we had to find a way to test the accuracy of that method. If the results of fingerprinting say that there are two instances of the advert in a certain recording, we had to know for sure how true that was.
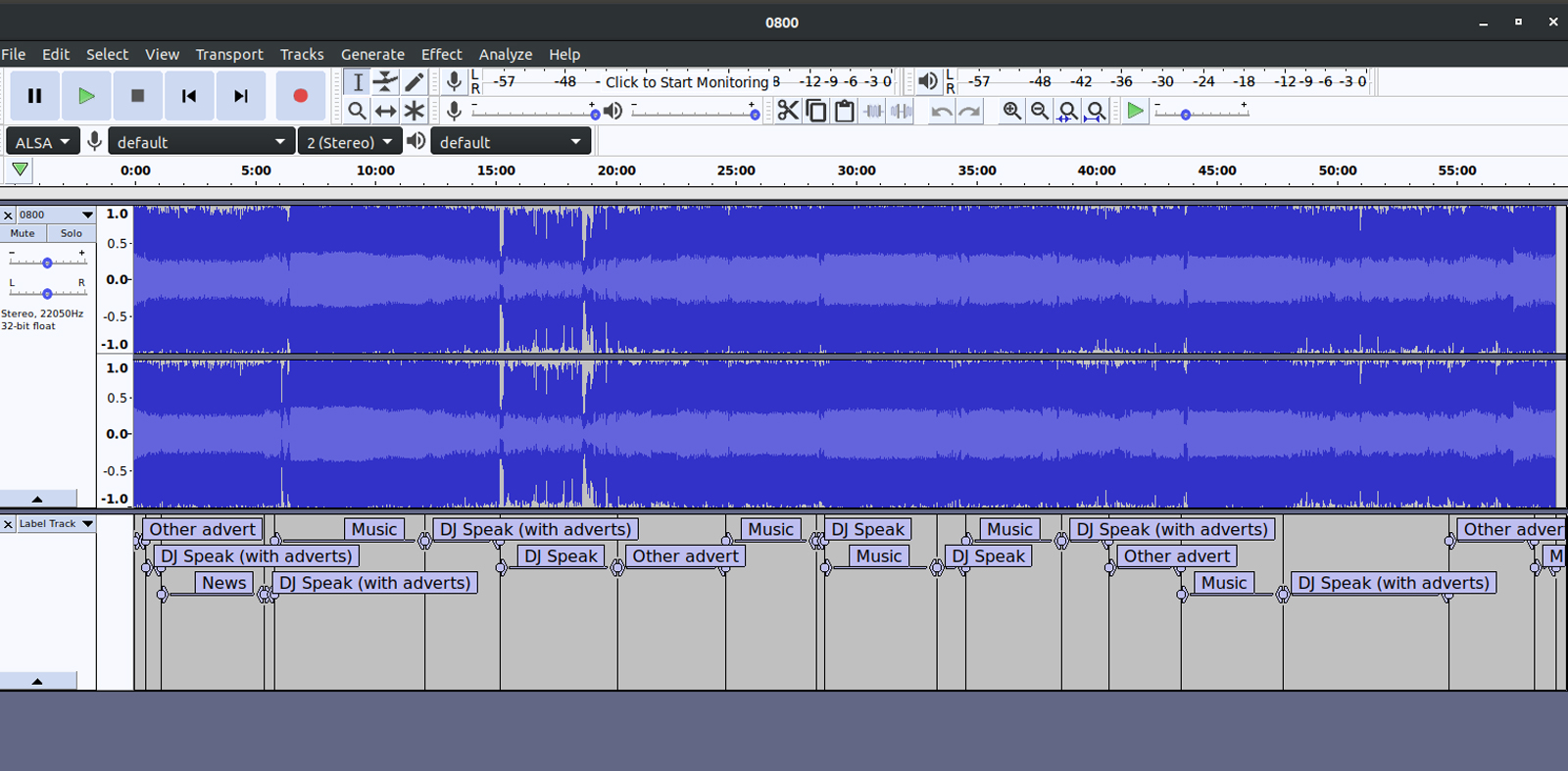
This meant that we would have to have some form of labeled data, labeled by we the human beings, in order to prove the computer right. We chose out samples of our huge pile of data and annotated them using Audacity, an amazing audio software.
A glimpse into what the data annotation process looks like:
Here is a sample of annotated data for an hour of radio:
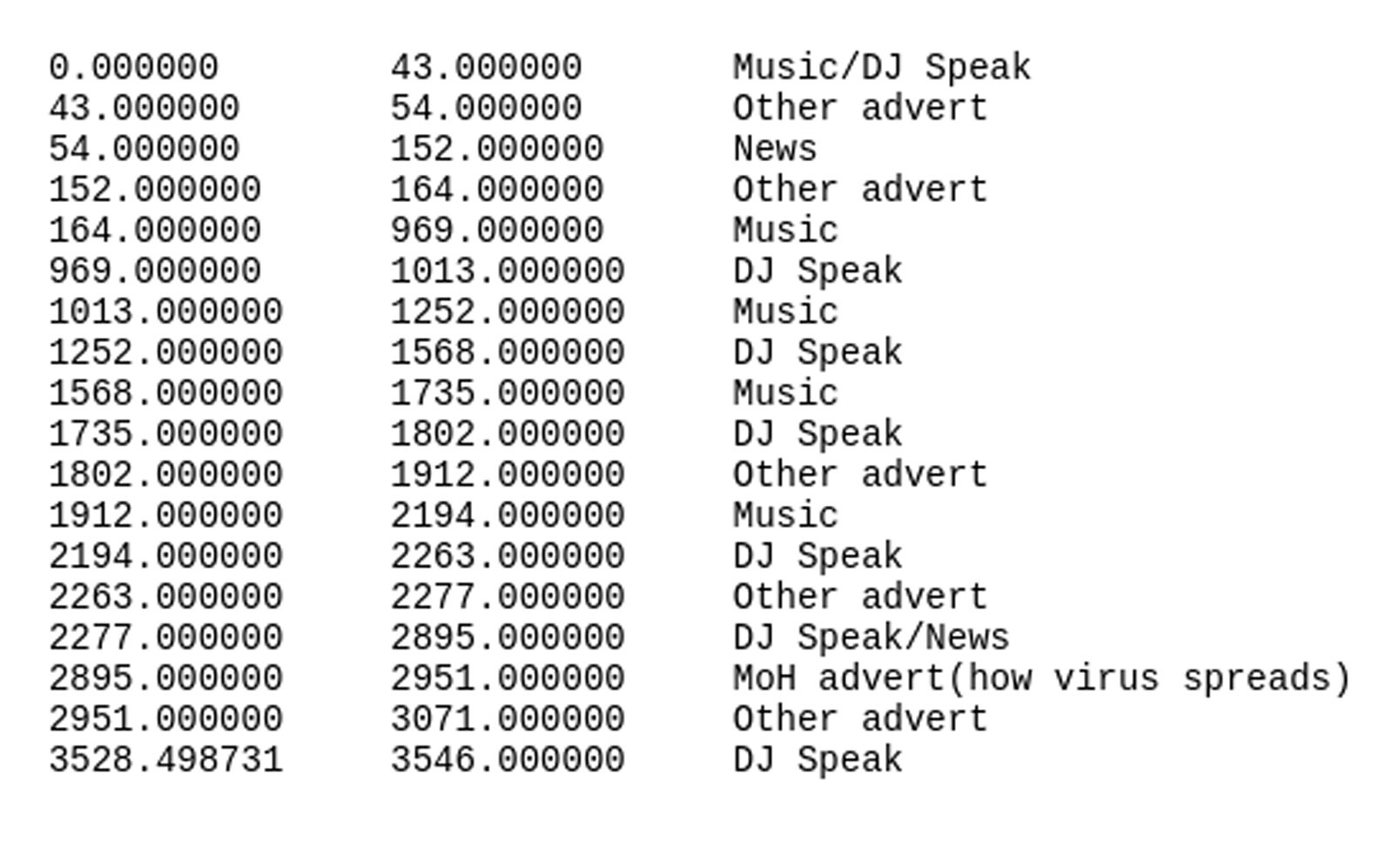
As the image shows, there are a lot of different things that go on in just an hour of radio, but what we are looking out for are the Ministry of Health COVID-19 adverts that run for just about a minute. Now that we know that the advert features in this particular hour, we can run the fingerprinting and see if it comes up with the same result.
FINGERPRINTING
First, what does fingerprinting even mean?
Audio fingerprinting is the process of digitally condensing an audio signal, generated by extracting acoustic relevant characteristics of a piece of audio content.
The short version of this is that it finds a way of identifying a piece of audio.
For our project, we ran a fingerprinting script using a Python tool called dejavu, with the aim of identifying the instances of the COVID-19 adverts played within the radio recordings.
CONCLUSION
After this process, what we get is the ability to choose any radio recording and find out the number of times the COVID-19 adverts are played. This can be extended according to what is required at a given time, for example checking how frequently the adverts play on an entire day on a particular radio station, or checking how they are dispersed throughout the day.
In that way, we achieve the goal of tracking the broadcasting of crucial COVID-19 information to the public, to make sure that safety information becomes common knowledge.