
People who don’t speak one of the world’s major languages have
difficulty accessing resources and in making their views heard. In
Uganda, for example, over forty languages are spoken …
Parallel Text Language Corpus Dataset for Key Ugandan Languages

Parallel Text Language Corpus Dataset for Key Ugandan Languages
- Ernest Mwebaze
- June 11, 2021
One of the ways that artificial intelligence shapes society is through language technology. Neural networks that can process language are the basis for being able to search the web, translate between languages, provide recommendations and carry out large scale analysis of text.
Machine translation has for a long time been the de facto NLP task. Unfortunately many African languages have not benefited from the advances of NLP because of limited language resources. Uganda is home to 43 languages and dialects, with most of them more spoken than written.
To contribute to language resources in Africa we set out to collect parallel text sentences for the 5 top languages in Uganda sufficient to enable a start on the machine translation task for Ugandan languages. Our approach was to build on existing efforts in this regard and make this the principal dataset for Ugandan language resources.
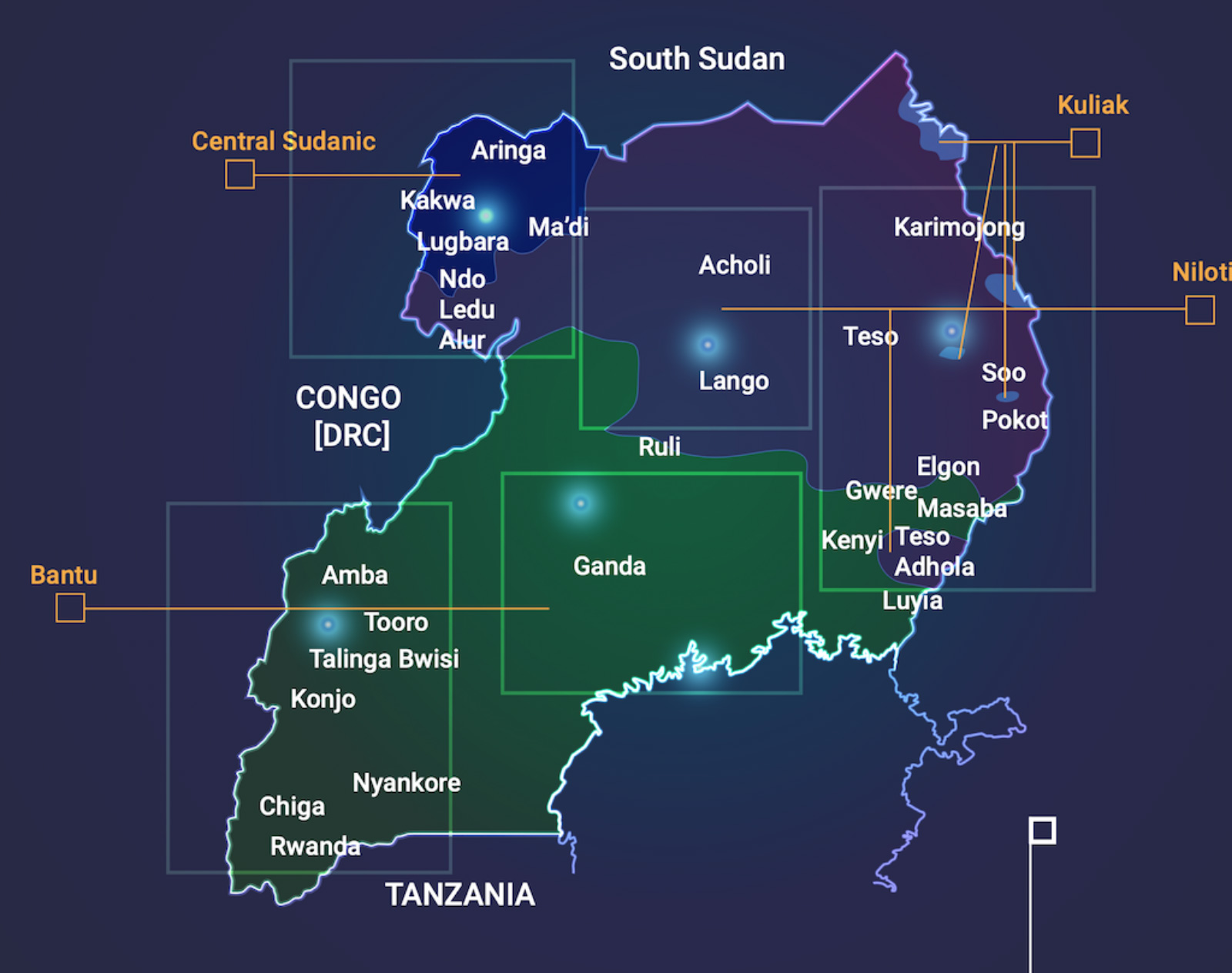
Uganda has 43 local/native languages used by large sections of the population. The map shows the spatial distribution of the languages and dialects spoken in Uganda. Within regions there are relatively similar languages/dialects with people able to understand and speak across these dialects, but these differences become more pronounced between different regions.
AFRICAN LANGUAGE TECHNOLOGY
Africa is a very linguistically diverse continent, with at least 1500 languages (compared to around 200 in Europe), for most of which no AI language technology has ever been developed. Almost all current effort on AI language technology is focused on English and a handful of other languages.
Another issue with the way this technology has evolved is that existing large models are generally trained with text trawled from the Internet, and have shown a tendency to reflect the harmful biases and divisiveness common in online speech.
Starting with our work in 2020 on social media monitoring, we’re interested in showing what’s possible with language AI technology in African languages, and how it can be done responsibly and inclusively.
PROJECT IMPLEMENTATION
This project started in October 2020 and was completed in Jan 2021. It was structured as a collaboration between Sunbird AI and the Makerere AI lab. Makerere AI lab has as its strengths, a solid track record of doing applied AI research and interfacing with the eventual clients of the research particularly government agencies in Uganda and direct beneficiaries like small holder farmers. Makerere AI lab is also located in Makerere University the leading university in Uganda and has access to a pool of good graduate and undergraduate research students.
THE DATASET
We collected a multilingual parallel text language corpus of 60,000 language phrases/sentences comprising of 10,000 English sentences/phrases and their corresponding translations in five under-resourced languages in Uganda: Luganda, Lugbara, Runyakitara, Acholi and Ateso.
The English sentences were obtained from the following data sources to capture the variety and context of use of language. The most likely use of this corpus will be for applications in these same source domains or similar.
- Social media (Facebook and Twitter)
- English Transcripts from radio data
- Online newspapers, articles, blogs and websites, e.g., Uganda Legal Information Institute (ULII).
- Text contributions from the Makerere University NLP community.
- Farmer responses from surveys.
To mitigate privacy and copyright concerns, we only used some of the sources as motivation for creation of similar but different phrases taking account of any privacy and bias concerns e.g. for social media, removing identifying tags and removing explicit references to sensitive attributes like religion and politics. The dataset can be downloaded here.
COVID-19 Social Media Analysis

We worked on language technology for social benefit with Ugandan health authorities in 2020, at the beginning of the Covid-19 pandemic. The public health emergency required new systems and policies …
Continue reading